Choose timezone
Your profile timezone:

Reproducibility is central to the open science discourse, promoting scientific integrity and strengthening society's trust in scientific results. Helmholtz is a central actor in the discussion on the promotion of reproducible and robust research on a national as well as international level.
Following the success of our first two (online) workshops of our reproducibility series (Enabling reproducibility in data science & Love your data? Make it reproducible!), we are excited to bring together the Helmholtz community in person for our third edition at the Telegrafenberg in Potsdam, hosted by the Helmholtz Centre Potsdam GFZ German Research Centre for Geosciences.
In our third workshop, again jointly organized by the Helmholtz Open Science Office and Helmholtz Information & Data Science Academy (HIDA), we will delve into the core of reproducible science and its transformative potential for science across disciplines. With this event we want to contribute in shaping the future of reproducible, robust, and transparent research within the Helmholtz community.
The workshop begins with two keynotes on reproducibility, one focusing on Image Data Analysis by Deborah Schmidt and the other on open science and research software engineering by Oliver Bertuch (both sessions will also be livestreamed). Following the keynotes, attendees can choose from a selection of three workshops that will equip you with the tools and insights needed to make reproducibility a cornerstone of your scientific endeavors.
The event will conclude with a shared lunch, providing ample networking opportunities for all participants.
Participation is free of charge (incl. lunch). Please register for the event by clicking on "Apply for Participation". During the registration process, you will be asked to choose one of the three workshops on offer. They will take place in parallel so you can only attend one.
The event will take place on the Telegrafenberg in Potsdam! Given that workshop seats are still available, registration will be open until October 31st, 2023.
Should you not be able to attend in person, the keynotes will be streamed in a hybrid setting. Registration for the keynotes only is possible on site or online and is open from September 27, 2023 until November 15, 1pm.
The Helmholtz Open Science Office supports the Helmholtz Association as a service provider in shaping the cultural change towards open science. It represents Helmholtz in various open science initiatives, is involved in third-party funded projects, and in this way communicates the Helmholtz positions on open science on a national and international level.
HIDA - the Helmholtz Information & Data Science Academy - is Germany’s largest postgraduate training network in the field of information and data science. We prepare the next generation of scientists for a data-intensive future of research.
Deborah Schmidt is head of the Helmholtz Imaging Support Unit at the Max Delbrück Center for Molecular Medicine in Berlin. Her team develops and maintains Album, a decentralized distribution platform for digital solutions to specific scientific problems. She is a media computer scientist experienced in basic research data analysis, human computer interaction, computer vision, deep learning, data visualization, and generative graphics. She is passionate about open science, frugal science, citizen science, and decentralized systems.
Oliver Bertuch is a research software engineer working on solutions for managing, publishing and archiving research data and research software. His mission is to bring these two worlds together to promote open science and reproducibility. Based at the Central Library, he works closely with the IQSS, Harvard, as part of the Dataverse Core Team (https://dataverse.org). His focus there is on issues such as containerisation and research software readiness of Dataverse repositories. As Co-PI of HERMES (https://software-metadata.pub), he is developing a new key infrastructure element for automated, metadata-rich research software publications.
Kainat Khowaja is a Statistical Consultant at the Core Facility Statistical Consulting team at Helmholtz Munich and Postdoc at Bielefeld University's Data Science Group. She brings expertise in statistics, machine learning, and data analytics. During her work at the Core Facility Statistical Consulting, she is offering support for research questions and addresses challenges in (bio-) statistics by ensuring the quality of analyses and applying modern statistical methods to data.
Adina Wagner is a research associate at the Forschungszentrum Jülich and doctoral researcher at the Heinrich Heine University Düsseldorf. She is a software developer for the DataLad project, an open source data management tool built upon Git and git-annex, and a proponent of open science, open source, and reproducible research.
Tracey Weissgerber leads the Meta-research and Automated Screening Group at the QUEST Center for Responsible Research within the Berlin Institute of Health at Charité – Universitätsmedizin Berlin. Her team’s research focuses on improving data visualization, methodological reporting, transparency, and reproducibility in scientific publications. Dr. Weissgerber organizes ScreenIT, a group of software developers and researchers who have created tools to screen preprints and papers for common problems and beneficial practices. She has also developed a series of courses where participants gain hands-on experience in designing and conducting meta-research (science of science) studies, writing and depositing protocols, and implementing other reproducible research practices in their own research.
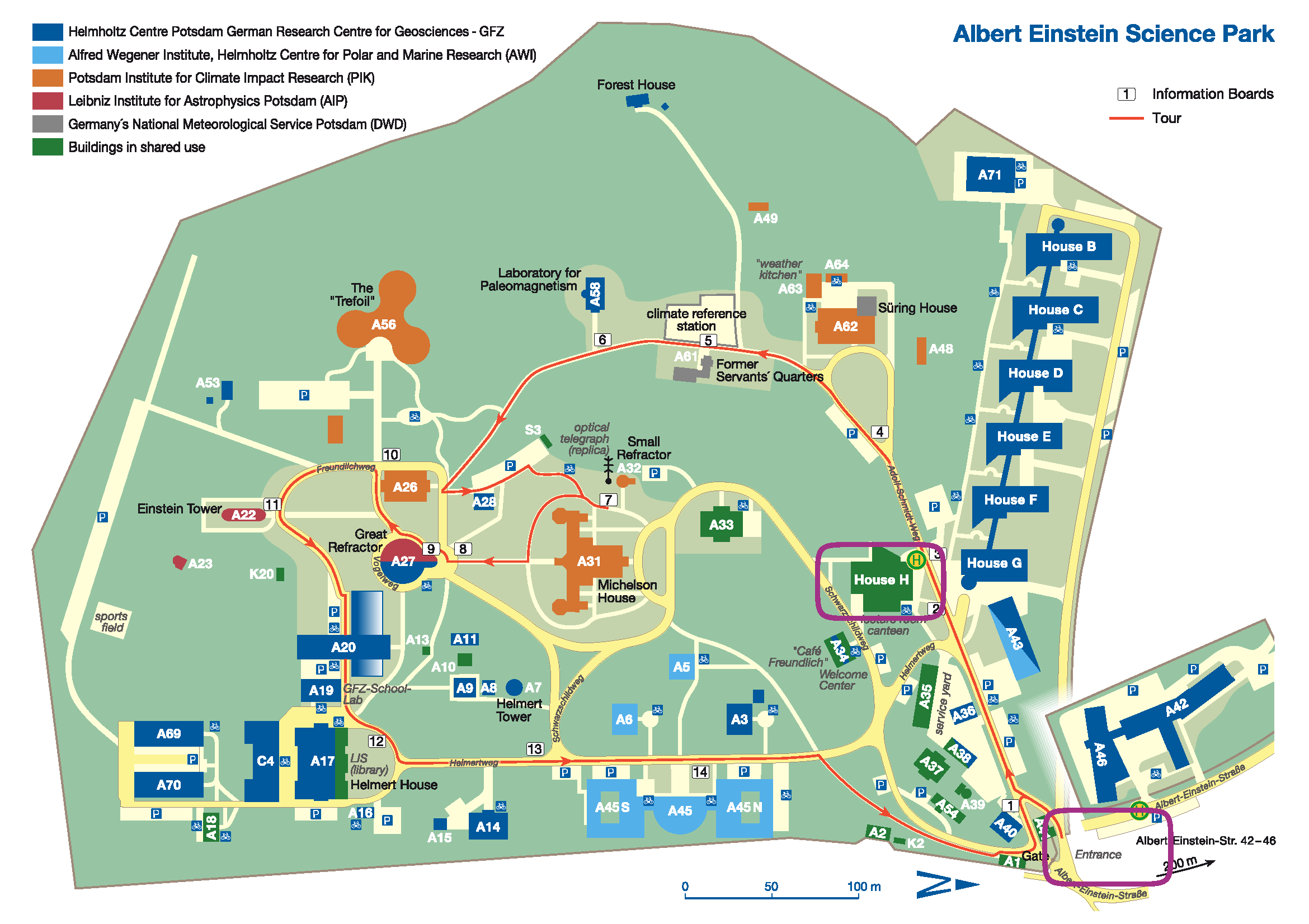
You can find information on how to get to the location here.
The workshop will take place in House H (purple box in the map).